교내에 푼 사람이 없는 문제이면서, 흥미로우면서 좀 배울 점이 있어보일만 한 문제를 선정해보았다.
https://www.acmicpc.net/problem/17469
17469번: 트리의 색깔과 쿼리
N개의 정점으로 구성된 트리가 있다. 각 정점은 1번부터 N번까지 번호가 매겨져있고, 1 이상 10만 이하의 자연수로 표현되는 색깔을 하나 갖고 있다. 루트는 1번 정점이고, 트리이기 때문에 임의
www.acmicpc.net
사실 이 문제를 풀기 하루 전에, 우리 학교 내에 정답자가 1명 생겨나
학교랭작에 아무런 도움이 되진 않았지만,
나름 배울점이 꽤 많은 문제였다.
의식의 흐름 및 해설
이제 트리 간선을 끊는다는 말만 보면 유니온파인드 및 오프라인 쿼리가 자동으로 1순위 후보에 생각날 정도가 됐다.
당연히 N이 10만이고, 간선을 끊은 상태로 dfs를 돌리는 순간 최소 시간복잡도가 O(N^2)이 되므로 오프라인쿼리 아이디어를 생각해냈다.
이 문제는 같은 컴포넌트에 몇 가지 색깔을 알고 있는지 파악하는 문제이기 때문에 유니온 파인드, set을 이용해야 한다.
사실 나는 set의 필요성을 잘 몰랐다. map은 자주 썼지만, set은 왜 써야 하는지 몰랐는데, 이 문제에서 set의 필요성을 알게 됐다.
Set은 집합으로, 자신의 집합에 몇 가지 종류가 있는지 중복을 제외하고 파악할 수 있게 해준다.
예를 들어, kth990303과 aru0504, choisk0531이 있다.
kth990303은 R, G, B 토큰, aru0504는 R, G, P 토큰, choisk0531은 G, L, A, B 토큰을 가지고 있다고 하자.
이 셋이 가지고 있는 토큰은 총 몇 종류인지 파악하기 위해선 물론 map을 활용해도 어찌저찌 풀리겠지만, map은 각 토큰이 얼마나 많은 사람에게 소유되고 있는지 파악할 때 쓰기 적합하고, set은 세 사람이 총 몇 종류의 토큰을 가지고 있는지 파악할 때 유리하다.
#include <iostream>
#include <set>
#include <map>
#include <vector>
#include <algorithm>
#define all(v) (v).begin(), (v).end()
using namespace std;
set<char> S[3];
map<char, int> m;
int main() {
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(false);
// init
S[0].insert('R'); m['R']++;
S[0].insert('G'); m['G']++;
S[0].insert('B'); m['B']++;
S[1].insert('R'); m['R']++;
S[1].insert('G'); m['G']++;
S[1].insert('P'); m['P']++;
S[2].insert('G'); m['G']++;
S[2].insert('L'); m['L']++;
S[2].insert('A'); m['A']++;
S[2].insert('B'); m['B']++;
cout << "================ set 중복 제거 하는 방법 알아보기 =============\n";
vector<char> ans;
set_union(all(S[1]), all(S[2]), back_inserter(ans));
cout << ans.size() << "\n";
for (auto i : ans) {
cout << i << " ";
}
cout << "\n=============== set 중복 제거 안하는 방법 알아보기 ============\n";
ans.clear();
merge(all(S[1]), all(S[2]), back_inserter(ans));
cout << ans.size() << "\n";
for (auto i : ans) {
cout << i << " ";
}
cout << "\n================ map으로 각 토큰 사용횟수 알아보기 =============\n";
for (auto i : m) {
cout << i.first << " " << i.second << "\n";
}
}
따라서 이 문제에서 각 집합이 알고있는 색깔의 종류 수를 파악해야 하므로
set을 이용하면 편리하다.
쿼리들을 저장한 후, 거꾸로 탐색하는 오프라인 쿼리를 이용할 것이다.
1번 쿼리일 경우, parent[a]와 a를 merge한다. 이 때 주의할 점이, set[b]의 원소들을 set[a]에 insert하여 각 집합의 색깔 종류를 merge할 때 최악의 경우 시간복잡도가 O(QN)이 나올 수 있다!
오프라인 쿼리로 O(QN)의 시간복잡도를 가질 정도면, 이 문제는 풀 방법이 없는걸까?
그렇지 않다. set을 작은 것에서부터 큰 것으로 합치면 합치는 횟수가 최대 lgN번으로 감소하게 되므로 union_find + small_to_large trick을 이용하면 O(lg^2(N))의 시간복잡도를 가지게 된다!
쿼리가 최대 100만 번이므로 총 시간복잡도는 O(Qlg^2(N))이 된다.
small to large trick 관련 글은 아래 블로그 포스팅을 참고하자. (사실 참고하지 않아도 이해하기 쉽다. 그냥 merge할 때 set[b]를 작은 것으로 swap해주고 set[b]를 set[a]에 합치면 된다.)
Small to Large Trick
Intro Small to Large Trick은 집합을 서로 합치는 연산을 최적화 할 때 사용하는 트릭입니다. (한국에서는 작은거 큰거 라고도 불리는 모양입니다.) 예를 들어 $n$개의 disjoint한, 크기가 1인 집합을 서로
ryute.tistory.com
merge코드는 아래와 같이 수정하면 된다.
// O(lgn) * small_to_large => O(lg^2(n))
bool merge(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return false;
// small to large -> set insert o(lgn)
if (S[a].size() <= S[b].size())
swap(a, b);
p[b] = a;
for (auto i : S[b]) {
S[a].insert(i);
}
S[b].clear();
return true;
}시행착오
처음엔 set을 이용하지 않고 배열로 갖가지 이상한 구현을 하다가 WA를 받았다.
이후, set을 이용했으나, small_to_large trick을 이용하지 않아서 17%에서 MLE를 받았다.
이후, small_to_large trick을 이용했으나, 부등호 순서를 반대로 해서 large_to_small trick (...)으로 해버려 2%에서 TLE, MLE를 받았다.
if (S[a].size() > S[b].size())
swap(a, b);S[b]를 S[a]에 insert해주는 것인데... S[b]를 크게 만들어버린 아주 멍청한 알고리즘을 짰따..

어지간한 멍청한.. 어지간한 멍청한.. 어지간한 멍청한..
이후 부등호 방향 수정 후 AC를 받았다.
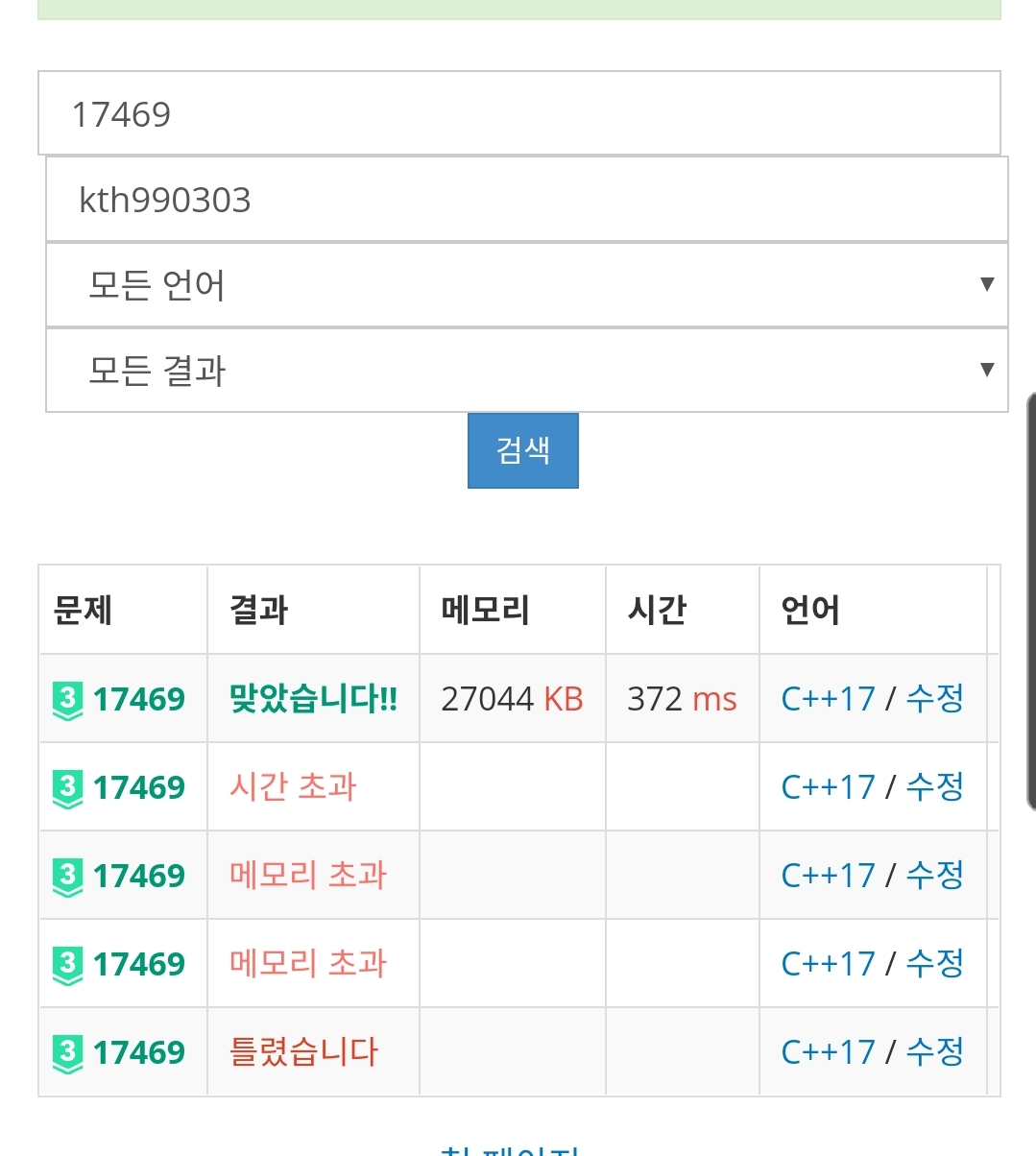
코드
// O(Qlg^2N)
#include <iostream>
#include <algorithm>
#include <vector>
#include <set>
using namespace std;
const int MAX = 100001;
int N, Q, p[MAX], parent[MAX];
vector<pair<int, int>> query;
set<int> S[MAX];
int find(int a) {
if (a == p[a])
return a;
return p[a] = find(p[a]);
}
// O(lgn) * small_to_large => O(lg^2(n))
bool merge(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return false;
// small to large -> set insert o(lgn)
if (S[a].size() <= S[b].size())
swap(a, b);
p[b] = a;
for (auto i : S[b]) {
S[a].insert(i);
}
S[b].clear();
return true;
}
int main() {
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(false);
cin >> N >> Q;
parent[1] = 1;
for (int i = 2; i <= N; i++) {
int n;
cin >> n;
parent[i] = n;
}
for (int i = 1; i <= N; i++) {
p[i] = i;
int n;
cin >> n;
S[i].insert(n);
}
query.resize(N + Q - 1);
vector<int> ans;
for (int i = 0; i < N + Q - 1; i++) {
cin >> query[i].first >> query[i].second;
}
for (int i = query.size() - 1; i >= 0; i--) {
int ch = query[i].first;
int a = query[i].second;
if (ch == 1) {
merge(parent[a], a);
}
else {
ans.push_back(S[find(a)].size());
}
}
for (int i = ans.size() - 1; i >= 0; i--) {
cout << ans[i] << "\n";
}
}small_to_large trick이 생각보다 시간복잡도에 미치는 영향이 컸으며, (O(N^2)->O(NlgN))
set의 중요성 또한 알게 된 문제였다.
그 외에 오프라인 쿼리에 대한 안목을 다시 한층 더 키우게 해준 좋은 문제였다.
'PS > BOJ' 카테고리의 다른 글
| [BOJ] 백준 1311. 할 일 정하기 1 (Gold I) (0) | 2021.05.20 |
|---|---|
| [BOJ] 백준 3037. 혼란 (Gold I) (0) | 2021.05.19 |
| [BOJ] 백준 2613. 숫자 구슬 (Gold II) (0) | 2021.05.16 |
| [BOJ] 백준 2800. 괄호 제거 (Gold V) (0) | 2021.05.15 |
| [BOJ] 백준 14461. 소가 길을 건너간 이유 7 (Gold II) (0) | 2021.04.23 |