우리는 객체지향을 배우면서 추상화의 장점을 배운다.
Java, Spring에서는 이 장점들을 적극적으로 활용할 수 있도록 굉장히 많은 지원을 해준다.
참고: https://kth990303.tistory.com/359
[JAVA] IoC, DI, DIP
친구와 얘기하던 중, Spring IoC, DIP 개념에 대한 얘기가 나왔다. 이 개념들은 구글링하면 워낙 잘 정리된 글들이 많아 별도로 작성하지 말까 고민도 했다. 하지만 해당 개념들은 객체지향에서 매우
kth990303.tistory.com
인터페이스, 추상클래스, DI 등의 장점에는 의존성이 적어진다는 점이 존재한다.
이러한 점 덕분에 구현을 하다가 if문이 굉장히 많이 나오거나, 추상화할 수 있게 리팩터링할만한 부분이 나온다면 우리는 추상화를 이용한 패턴을 고려하게 된다.
그런데 추상화도 어떻게 하냐에 따라 차이가 크다는 것을 최근에 느끼게 됐다.
제목을 단순히 `전략 패턴 적용으로 인한 추상화 장점` 이 아닌, `전략 패턴 안에 전략 패턴 어쩌고`로 지은 이유이다. 구조가 복잡해질수록 패턴을 떠올리기 꽤 어려워진다는 걸 느꼈다. 이번 포스팅에선 전략패턴 내에서, 또 전략 패턴을 적용해 더욱 의존성을 줄여보는 사례를 적어보려 한다.
(특별한 패턴은 아니고, 사실상 그냥 전략 패턴 장점 관련 포스팅이라 보면 된다. 이중으로 있어서 헷갈려서 기록하는거라...)
예시 코드를 만들어서 포스팅을 작성해보려 한다.
실제 코드는 이보다 훨씬 복잡했으며, 따라서 예시 코드에서 더 좋은 방안이 존재할 여지가 충분히 존재한다.
상황
수많은 몬스터들이 존재한다.
우리는 각각의 몬스터들이 어떠한 몬스터인지 생김새로 분류하는 프로그램을 만들어야 한다.
몬스터 종류는 아래와 같다.
- 귀여운 몬스터
- 잘생긴 몬스터
- 못생긴 몬스터 (귀엽거나 잘생기지 않으면 모두 못생겼다고 간주한다)
그리고 못생긴 몬스터들은 굉장히 많기 때문에 조금 더 세세하게 분류하려 한다.
- 못생긴 몬스터
- 머리가 커서 못생긴 몬스터
- 뚱뚱해서 못생긴 몬스터
- 악취가 나서 못생긴 몬스터
그리고 해당 프로그램에는 생김새 분류 외에, 공격력, 방어력 등등 다양한 분류 코드가 이미 존재하는 상황이라고 가정한다.
타 분류 코드에는 영향을 미쳐선 안된다.
(이유를 어떻게 짜낼까 고민하다가 잘 생각이 안나서 위와 같이 적었다...)
처음에 생각했던 방향
추상화 장점 부분부터 적을 것이라 좀 길다.
지루하다 싶으면 `개선된 방향` 제목에 해당되는 부분부터 읽으면 된다.
먼저 각 몬스터들이 가지고 있는 Property 클래스들을 만들어야 할 것이다.
그리고 이 Property를 이용하여 몬스터를 분류하는 MonsterChecker가 존재하게 한다.
MonsterChecker 코드를 아래와 같이 만들고 싶진 않을 듯하다.

이 경우에는 몬스터 분류 조건이 계속해서 추가될수록, 코드의 변경이 요구되는 케이스이다.
물론 예시에서는 요구사항이 매우 간단하므로 문제가 되지 않는다.
하지만, case work가 굉장히 복잡해지면 코드 내에서 어떤 부분을 수정해야 하는지, 어떻게 조건을 추가해야 되는지, 해당 요구사항 추가로 인해 다른 조건들이 바뀌지는 않는지 확인해야되고 이는 매우 번거롭다. 클래스끼리의 의존성도 골치아프지만, 클래스 내에서 변수, 함수끼리의 의존성도 상당히 골치아프다.

따라서 CuteMonsterProperty, HandsomeMonsterProperty 등을 추상화하는 MonsterProperty를 만들어주었다. 추상화의 장점을 챙기기 위해서이다. 이렇게 하면 장점이 MonsterChecker 코드가 간단해진다.

MonsterChecker에서는 List<MonsterProperty>를 가진다.
그리고 이를 이용하여 filter를 이용해 귀여운 몬스터인지, 잘생긴 몬스터인지 등등 분류를 시작한다.
분류 조건이 추가되어도 해당 클래스에서 변경할 부분이 존재하지 않는다.
MonsterProperty 코드는 아래처럼 된다.


CuteMonsterProperty, HandsomeMonsterProperty 등. 각각의 Property 끼리의 의존성이 존재하지 않는다.
분류 조건이 추가되더라도 타 분류조건과의 의존성을 고려하지 않고 편하게 코드를 작성하면 된다.
UglyMonsterProperty는 추가로 고려해야될 게 존재한다.
`머리가 커서 못생겼는지`, `뚱뚱해서 못생겼는지`, `악취가 나서 못생겼는지`에 대해서도 분류를 해주어야 한다.
따라서 아래와 같이 UglyMonsterProperty는 인터페이스로 만들어주고, UglyDueTo... 클래스들을 추가해주었다.

몬스터를 분류하는 책임을 맡은 MonsterChecker 클래스에서는 List<MonsterProperty>를 받아 이를 분류한다.
UglyMonsterProperty의 하위 클래스들인 UglyDueToBigHeadMonsterProperty, UglyDueToStinkyMonsterProperty 등은 결국 MonsterProperty의 자식 클래스이다. 따라서 MonsterChecker의 check에서 돌았던 filter 대상에 포함된다.
따라서 모든 Property들을 돌면서 만족하는 조건에 몬스터들이 분류가 된다.
즉, `머리가 커서 못생긴 몬스터`를 분류하는 경우에는 아래의 로직을 타게 된다.
checker: 귀여운지/못생겼는지/잘생겼는지
->
uglyMonsterProperty의 print로 인한 checkWhyUgly: 머리가큰지/뚱뚱한지/악취가나는지
개선된 방향
위와 같은 설계는 꽤나 괜찮은 설계이다.
각 분류 기준끼리 의존성도 거의 없고, 코드도 깔끔하기 때문이다.
하지만 더 좋은 개선방법이 존재한다.
현재 로직에서 `머리가 커서 못생긴 몬스터`를 분류하는 경우에는 아래의 로직을 타게 된다.
checker: 귀여운지/못생겼는지/잘생겼는지
->
uglyMonsterProperty의 print로 인한 checkWhyUgly: 머리가큰지/뚱뚱한지/악취가나는지
여기서 문제는 바로 UglyDueToBigHeadMonsterProperty, UglyDueToFatMonsterProperty,UglyDueToStinkyMonsterProperty 를 분류하는 책임이 사실상 UglyMonsterProperty가 아닌, 한 층 상위인 MonsterProperty (상위 객체)에 있다는 점이다.
다시 한번 MonsterChecker 코드를 보자.
monsterProperties 에는 UglyDueToBigHeadMonsterProperty, UglyDueToFatMonsterProperty, UglyDueToStinkyMonsterProperty 도 포함된다. MonsterProperty의 하위 구현체이기 때문이다.
monsterProperties에는 아래 클래스들이 포함된다.
- 귀여운지
- 잘생겼는지
- 못생겼는지 - 머리가 커서
- 못생겼는지 - 뚱뚱해서
- 못생겼는지 - 악취가 나서
따라서 못생긴 몬스터의 경우 monsterChecker 클래스의 monsterProperties.filter에 3번 선택받게 될 것이다.
(귀여운 몬스터, 잘생긴 몬스터는 1번씩만 걸리게 된다.)

머리가 크거나, 뚱뚱하거나, 악취가 나는 몬스터들은 check 조건에 만족하므로 print 대상이다.
따라서 MonsterChecker::filter에는 5개 (귀엽거나, 잘생겼거나, 머리가 크거나, 뚱뚱하거나, 악취가 나거나) 중 3개에 만족하게 되며, MonsterChecker::forEach에 의해 위 사진의 print 조건이 3번 실행되게 된다.
print가 3번 실행되는 게 문제면,
filter에 있는 check 조건에서 각각 한 가지 분류조건에만 true가 반환되게
check 함수를 수정하면 되는 거 아닌가?
return monster.isUgly() && body.hasBigHead() 와 같이 작성하면 되지!
그렇다.
사실 check 함수에서 머리가 크거나, 뚱뚱하거나, 악취가 나는지 여부까지 파악할 수 있게 하면 된다.
그러면 어떠한 이유로 못생겼는지 또 다시 불필요하게 확인할 필요가 없다.
애초에 이중for문이 되지 않게 단일 for문으로 바꿀 수 있다면 바꾸는게 좋다.
하지만 check 함수의 인자는 왜 못생겼는지 확인하는 body를 받지 않는다.
따라서 check에서 왜 못생겼는지까지 체크하려면 check 함수 인자에 Monster, attackForce 뿐만 아니라 Body 까지 존재하게 수정해주어야 한다. MonsterProperty 클래스의 check 함수 자체를 바꾸기에는 영향범위가 너무 크다.
그리고 어떻게 보면 MonsterChecker에서 너무 디테일한 책임까지 다 가지고 있다는 문제점도 여전히 존재한다.
어떻게 하는 것이 좋을까?
다시 한 번 MonsterChecker 클래스로 가보자.
문제되는 부분은 monsterProperties.filter 에 3개의 MonsterProperty 클래스가 대상이 되면서 print 함수가 3번이나 호출되는 것이었다.
따라서 MonsterChecker의 check 함수의 filter에 UglyDueToBigHeadMonsterProperty, UglyDueToFatMonsterProperty,UglyDueToStinkyMonsterProperty가 포함되지 않게 하면 된다.
즉, filter 조건에 (귀여운지/잘생겼는지/못생겼는지) 만 포함되게 하면 된다.
filter에 어떠한 이유로 못생겼는지까지는 필요하지 않다.
그런데 UglyDueToBigHeadMonsterProperty, UglyDueToFatMonsterProperty,UglyDueToStinkyMonsterProperty 의 상위 인터페이스인 UglyMonsterProperty는 인터페이스이므로 List<MonsterProperty>에 넣을 수 없다.
그렇다면?
List<MonsterProperty>에 넣어줄 수 있으면서, UglyDueToBigHeadMonsterProperty, UglyDueToFatMonsterProperty,UglyDueToStinkyMonsterProperty 의 상위 클래스를 하나 만들어주면 될 것 같다!
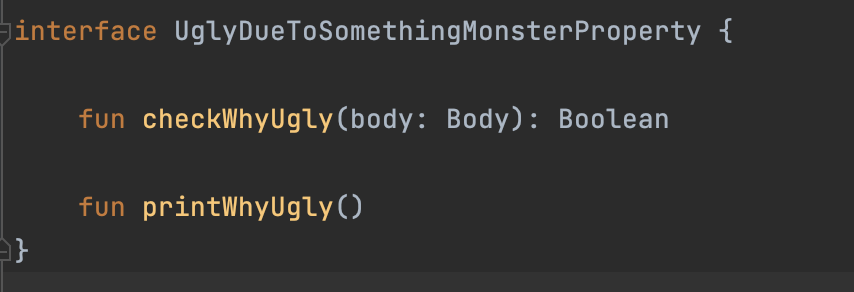
상위클래스명 이름이 UglyMonsterProperty인 게 적절할 듯하여, 기존 UglyMonsterProperty 인터페이스 명을 UglyDueToSomethingMonsterProperty로 변경해주었다.

그러면 기존 인터페이스인 UglyDueToSomethingMonsterProperty (이전의 UglyMonsterProperty 인터페이스) 는 아래와 같이 MonsterProperty의 check, print 함수를 override할 필요가 없어진다.
MonsterProperty가 아닌, 상위클래스에 해당되는 UglyMonsterProperty에서 관리하기 때문이다. 따라서 독자적인 인터페이스로 변경된다.
이렇게 만들어주면 `머리가 커서 못생긴 몬스터`를 분류하는 경우에는 아래의 로직을 타게 된다.
MonsterChecker의 filter: 귀여운지/못생겼는지/잘생겼는지 (못생겼는지에서 걸림)
->
새로 만들어준 UglyMonsterProperty 클래스에서 print 수행 (print는 1번만 수행!)
(UglyMonsterProperty 클래스에서 왜 못생겼는지의 분류 책임을 가지고 있음.)
filter에서는 아래 3가지만 필터링한다
- 귀여운지
- 못생겼는지 (UglyMonsterProperty 클래스를 만들어주었기 때문)
- 잘생겼는지
즉, 아래와 같이 설계를 변경한 것이다.
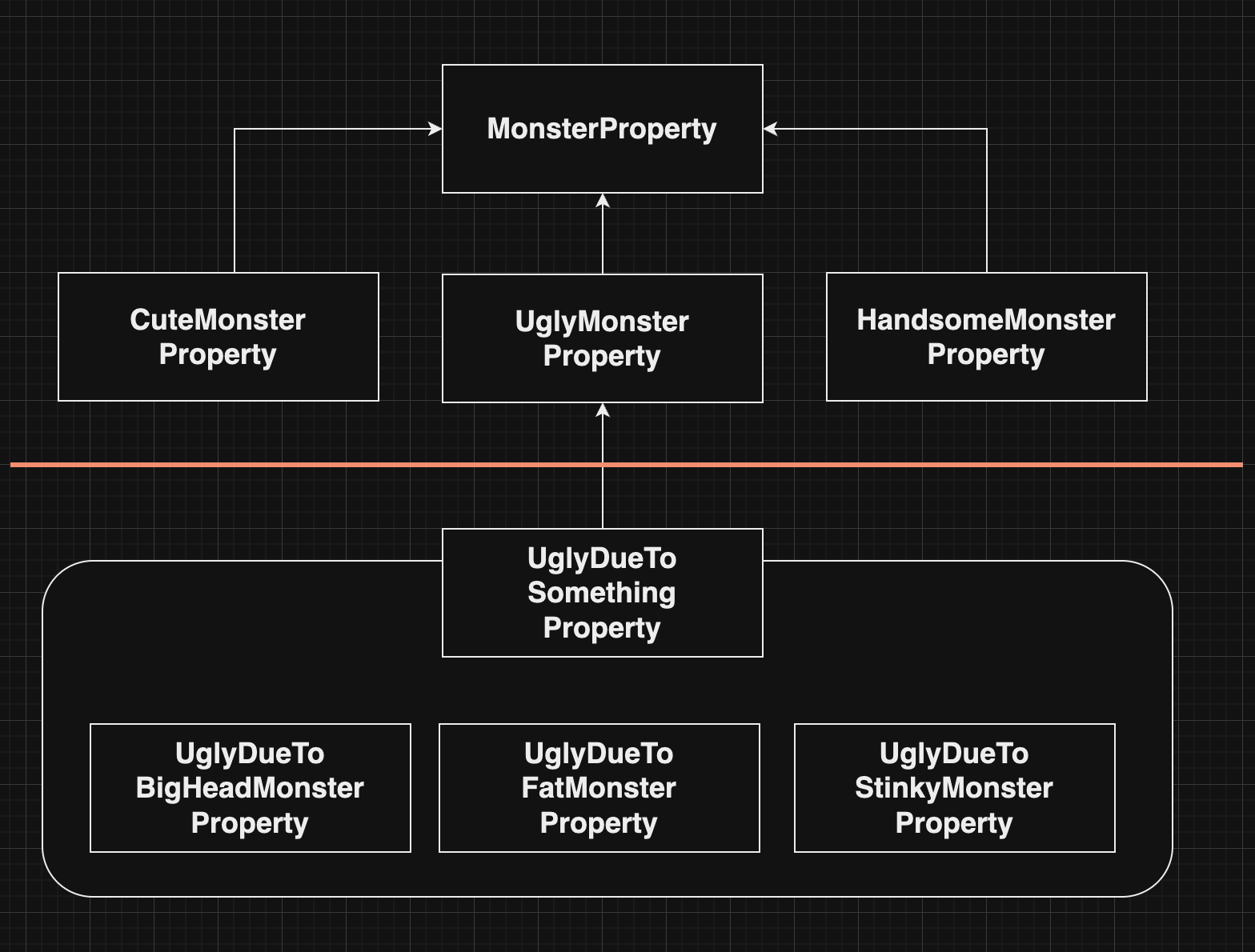
사실 까놓고 보면 전략패턴 안에 전략패턴을 넣은 것이다.
위 사진의 구조에서 빨간선을 기준으로 책임을 분리하여 의존성을 줄였음을 알 수 있다.
마치며
뒤로 갈수록 조금 중구난방하게 설명을 해서 이해가 잘 안될 수 있다.
한줄 요약하자면 아래와 같다.
- 추상화를 이용하고, 하위 클래스에서 구현하다가 또 추상화할게 보이면 추상화하자.
다만, 처음부터 추상화를 고려하여 설계하는 것보다 구현하다보니 추상화할게 보일 때 하는 것이 좋은 듯하다.
사실 이 경험은 회사에서 코드 짜다가 경험하게 된 것이다.
밸리데이션 정책이 굉장히 복잡해서 전략 패턴을 이용했었다. 코드를 보신 페어분께서 하위 밸리데이션에서의 책임이 상위쪽에 있는 것을 바로 캐치하시고, 추가로 추상화할 부분을 알려주셨다.
추상화. 나름 많이 써보았다고 생각했다.
그런데 구조가 복잡해지니까 헤매는 내 모습을 발견했다.
많이 경험해보면서, 그리고 리팩터링해보면서 경험치를 쌓아가야겠다.
'Kotlin > Kotlin | Spring 학습기록' 카테고리의 다른 글
| [Kotlin] mock 테스트를 작성할 때 기억하면 좋은 점들 (3) | 2024.10.12 |
|---|---|
| [Kotlin] Refresh Token을 Redis에 저장하는 코드 작성 및 고찰 (0) | 2023.03.08 |
| [Spring] ArgumentResolver 사용 시 주의점 (feat. OSIV) (3) | 2023.02.26 |
| [Kotlin] Swagger 문서에 DTO 필드 required 표시해주기 (0) | 2023.02.21 |
| [Kotlin] kotlin은 왜 Java와 달리 Checked Exception을 제공하지 않을까? (4) | 2022.11.15 |