SRE 분야에 대해 공부하던 중, timeout 원인을 찾는 과정에서 네트워크 레이어부터 분석하는 경우가 많다는 것을 느꼈다. 실제로 내가 현재 진행하고 있는 사이드 프로젝트에서 모니터링 및 장애대응 업무를 주로 맡고 있기 때문에 해당 내용에 관심이 생기기 시작했다. 아직까지 규모가 작기 때문에 504 Gateway time-out이 뜬 경험은 거의 없어서 네트워크 패킷까지 뜯어볼 일은 없었다. 이번 기회에 한 번 뜯어보면 언젠가 도움이 되지 않을까 하여 뜯어보기로 결정했다.
참고) 해당 포스팅은 개인 학습기록이므로 틀린 내용이 존재할 수 있습니다. 틀린 내용을 혹시 발견하셨다면 댓글 부탁드립니다.
ubuntu에서 tcpdump 캡처하는 방법
1. 우분투 서버에 접속한다.
ssh -i {pem KEY} ubuntu@{server-ip}
2. 현재 시스템에서 사용 가능한 네트워크 인터페이스 목록 확인
tcpdump --list-interfaces
이더넷 인터페이스에 해당되는 eth0이 존재한다.
마침 Connected이기도 하니, 해당 네트워크 인터페이스에서 tcpdump 파일을 따보려 한다.
3. 해당 네트워크 인터페이스의 패킷 캡처
sudo tcpdump -i eth0 -w {캡처파일명}.pacp해당 명령어를 입력하면 tcpdump: listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes 문구가 뜨면서 계속 대기중일 것이다. 적당한 시점에서 `control + c` 를 눌러주면 그 시점까지의 패킷을 캡처한다.
4. scp 명령어 (또는 그 외 방법)를 통해 파일을 로컬로 전송
scp ubuntu@{server-ip}:{캡처파일명} {local-directory}참고로 나는 이 과정에서 permission denied가 떴다. (웬만해선 문제가 없을 듯)
원격로그인 및 접속 권한을 허용해줬음에도 불구하고 해당 에러가 뜨는 이유는 모르겠지만, 그냥 github private repo에 push했다(...)
와이어샤크로 tcpdump 확인하기 + AWS ALB idle timeout 설정
한번 pcap 파일을 와이어샤크로 열어서 tcpdump 파일의 네트워크 패킷을 확인해보자.
참고로 해당 애플리케이션과 aws ALB 환경은 아래와 같다.
[상황 1]
- 스프링 애플리케이션 session timeout: 5초 (테스트 용도로 일부러 짧게 설정했다.)
- AWS ALB idle timeout: 3초 (테스트 용도로 일부러 짧게 설정했다.)
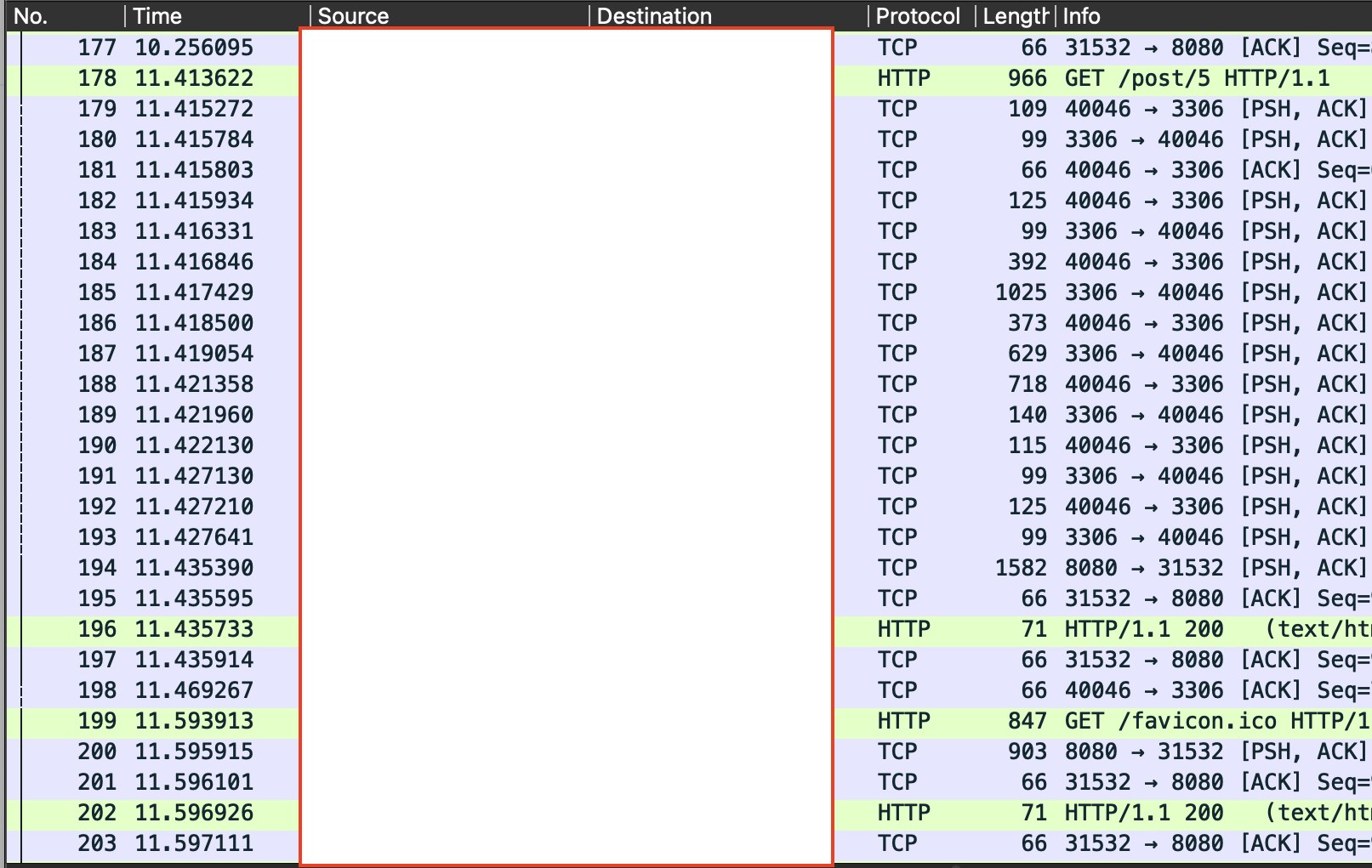
실제로 178번에 보낸 GET `/post/5` 요청이 들어오고, 약 0.02초 후인 196번에 HTTP/1.1 200 OK를 받은 모습을 확인할 수 있다.
중간에 PSH 패킷은 클라이언트 측에서 데이터를 즉시 전송하라고 요청하는 패킷이라고 한다. 실제로 PSH 패킷이 있다고 해도, 데이터가 올바르게 전송됨이 보장됐으면 문제있는 상황은 아니라고 한다.
참고로 실제로 좀 더 최적화가 된 경우에는 거의 패킷번호 차이 1만으로 요청, 응답을 주고받는 듯하다.
AWS ALB의 idle timeout은 스프링 애플리케이션 timeout보다 짧게 설정하는 것을 권장하고 있다.
We also recommend that you configure the idle timeout of your application to be larger than the idle timeout configured for the load balancer. Otherwise, if the application closes the TCP connection to the load balancer ungracefully, the load balancer might send a request to the application before it receives the packet indicating that the connection is closed. If this is the case, then the load balancer sends an HTTP 502 Bad Gateway error to the client.
출처: https://docs.aws.amazon.com/elasticloadbalancing/latest/application/application-load-balancers.html#connection-idle-timeout
간단하게 번역해보자면 아래와 같다.
스프링 애플리케이션의 session timeout이 더 짧을 경우, 애플리케이션 커넥션이 끊긴 상태에서 ALB는 이를 모른 상태로 요청을 보내게 될 것이다. 그렇게 되면 서버는 응답이 불가능해 502 Bad Gateway를 받게 될 수 있다고 한다.
위 상황도 문제지만, 아래 상황도 문제다.
애플리케이션에서 api 응답시간이 너무 길어서 session timeout 만큼 기다려야되는 경우를 생각해보자.
만약 스프링 애플리케이션의 session timeout이 ALB 의 idle timeout보다 더 짧다고 해보자.
스프링 애플리케이션은 session timeout 시간 후 504를 반환할 것이다. 하지만 ALB와의 커넥션은 아직 끊기지 않았다. 따라서 서버는 이미 timeout을 반환했음에도 불구하고 유저는 계속해서 응답을 대기하게 된다. 그리고 ALB idle timeout이 지나면 유저는 504 Gateway time-out 응답을 받게 된다.
위 패킷 캡처본은 스프링 애플리케이션 session timeout이 ALB idle timeout보다 길었다. 따라서 크게 문제되는 상황이 아니었다.
다행히 ALB idle timeout이 더 짧기 때문에 클라이언트는 ALB idle timeout 만큼의 시간동안만 대기한 후 응답을 받을 수 있게 된다. (물론 응답은 504 Gateway Time-out으로, 좋은 상황은 아니긴 하지만 말이다.)
다른 상황을 한 번 살펴보자.
[상황 2]
- 스프링 애플리케이션 session timeout: 5초 (테스트 용도로 일부러 짧게 설정했다.)
- 특정 POST api 응답은 5초를 넘어가게 설정
- AWS ALB idle timeout: 10초

18번에 해당되는 3.15초에 호출한 `GET /post/` 요청이다.
우리는 3.15초에 해당 요청을 보냈고, 스프링 애플리케이션에서 timeout을 5초로 설정해놨다. 그렇기 때문에 아무리 늦어도 약 8~9초 대에는 504 응답을 받고 싶다.
하지만 실제 결과는?

무려 10초나 지난 후에야 504 Gateway time-out 응답을 유저가 받게 된다!
ALB idle timeout이 10초이기 때문에 유저는 10초간 손가락만 빨며 대기해야되는 입장이 돼버린 것이다.
그렇기 때문에 AWS ALB의 idle timeout은 애플리케이션 session timeout보다 짧은 것이 확실히 좋을 듯하다.
참고로 스프링의 default session timeout은 1800초(30분), AWS ALB의 default idle timeout은 60초이기 때문에 별도 설정을 하지 않았다면 권장되는 환경에서 이용하고 있는 것이다.
마치며
사실 aws 공식문서에 써져있는, ALB idle timeout이 더 긴 상황에서 502 Bad Gateway를 보고 싶었는데, 생각보다 쉽지 않았다.
HTTP는 기본적으로 keep-alive 하게 커넥션을 유지하고 있기도 하고 AWS ALB의 idle timeout은 애플리케이션 상황에 따라 유동적으로 변하면서 관리될 수 있기 때문이라고 한다.
참고로 tcpdump을 활용한 네트워크 분석을 통한 SRE 업무는 해당 포스팅에서 설명한 것보다 훨씬 다양하다.
아래 글이 개인적으론 정말 재미있었는데, 관심있는 분들은 읽어보면 좋을 듯하다.
https://brunch.co.kr/@alden/38
tcpdump를 활용한 타임아웃 분석
시스템 엔지니어의 주요 업무 중 하나는 애플리케이션에서 발생하는 타임아웃의 원인 분석입니다. 특히 요즘처럼 서비스들 간에 API를 통해서 연동을 하는 경우에는 타임아웃이 더욱 빈번하게
brunch.co.kr
나중에 규모가 큰 애플리케이션에 참여하게 된다면 네트워크 패킷을 만질 일이 많지 않을까?
그때가 언제가 될지는 나도 정말 궁금하다.
너무 먼 미래만 아니였음 좋겠다 ㅎㅎ
참고
- AWS ALB의 time out에 관하여: https://reaperes.medium.com/aws-alb-%EC%9D%98-idle-timeout-%EC%97%90-%EA%B4%80%ED%95%98%EC%97%AC-7addb8bfb886
- 로드밸런서의 keep-alive 옵션: https://trend21c.tistory.com/2258
- tcpdump를 활용한 타임아웃 분석: https://brunch.co.kr/@alden/38
- 우아한형제들 SRE 팀에서 장애의 root cause를 찾고 재발방지하는 방법: https://techblog.woowahan.com/2700/
- 패킷 유실을 고려한 Connection/Read Timeout 설정: https://alden-kang.tistory.com/20
'Infra > Aws' 카테고리의 다른 글
| [AWS] 1달간의 SES 샌드박스 계정 탈출일지 (2) | 2023.05.23 |
|---|---|
| [Infra] AWS SNS+Chatbot로 슬랙 알림받기(Feat. AWS Budgets) (0) | 2023.05.22 |
| [230504] AWS Summit Seoul 2023 후기 (17) | 2023.05.04 |
| [AWS] SES를 이용한 메일 전송 기능 구현 (0) | 2023.04.25 |
| [AWS] CloudWatch + Lambda로 slow query 발생 시 Slack 알림 보내기 (0) | 2023.04.21 |