해당 글에서는 spring data jpa에서의 left outer join, fetch join, 커버링 인덱스에 대해 다룹니다.
사이드 프로젝트 `모카콩`의 Wiki에 작성한 글에 해당된다.
해당 프로젝트 github: https://github.com/mocacong/Mocacong-Backend
GitHub - mocacong/Mocacong-Backend: 모카콩 백엔드
모카콩 백엔드. Contribute to mocacong/Mocacong-Backend development by creating an account on GitHub.
github.com
들어가며
모카콩에서는 카페에 대한 리뷰를 작성할 때마다 다양한 작업을 해주고 있습니다.
리뷰에는 평점, 해당 카페에 대한 스터디 타입(혼코딩하기 좋은지, 팀플하기 좋은지), 세부정보(와이파이, 콘센트 등)에 대한 내용을 작성할 수 있습니다. 특정 카페에 대한 리뷰는 한 사람이 여러 개를 달 수 없습니다. 리뷰가 작성될 때마다 카페에서는 해당 리뷰를 반영한 정보로 업데이트해주어야 합니다.
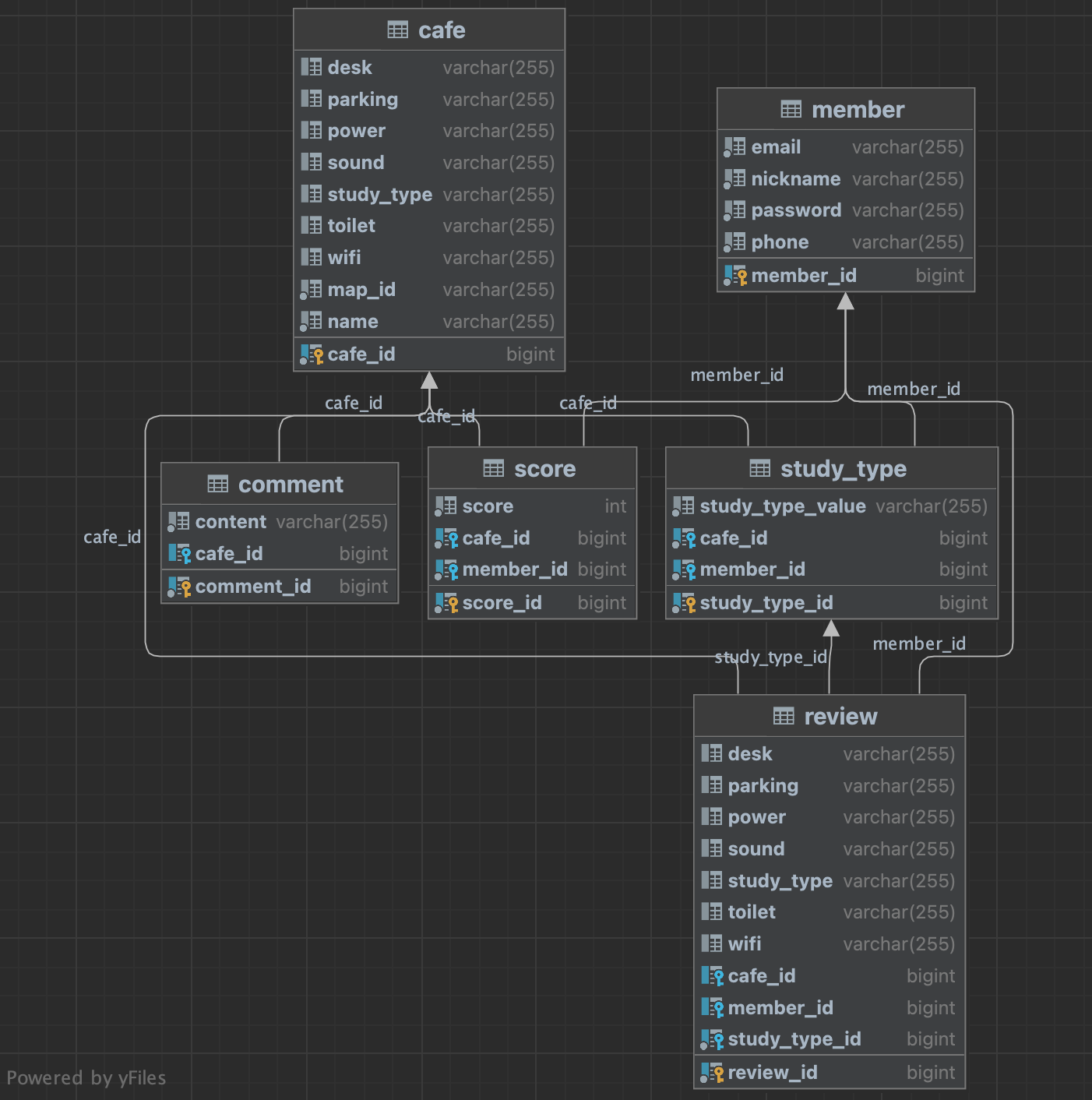
문제가 되는 상황
리뷰에 수많은 정보들이 담겨있다보니, 카페에 대한 리뷰를 작성할 때 수많은 쿼리들이 나가게 되는데요.
그 중에서도 가장 대표적으로 메서드 성능이 좋지 않은 경우는 아래 두 가지였습니다.
1. 리뷰 작성 후 해당 카페의 study type을 갱신하는 과정
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private String findMostFrequentStudyTypes(Long cafeId) {
List<StudyType> soloStudyTypes = studyTypeRepository.findAllByCafeIdAndStudyTypeValue(cafeId, SOLO_STUDY_TYPE);
List<StudyType> groupStudyTypes = studyTypeRepository.findAllByCafeIdAndStudyTypeValue(cafeId, GROUP_STUDY_TYPE);
if (isEmptyStudyTypes(soloStudyTypes, groupStudyTypes)) {
return null;
}
if (soloStudyTypes.size() > groupStudyTypes.size()) {
return SOLO_STUDY_TYPE;
}
if (soloStudyTypes.size() < groupStudyTypes.size()) {
return GROUP_STUDY_TYPE;
}
return BOTH_STUDY_TYPE;
}
|
cs |
모카콩에서는 특정 카페에 대한 스터디 타입(혼코딩하기 좋은지, 팀플하기 좋은지) 리뷰를 작성할 수 있습니다.
해당 카페가 혼자 공부하기에 좋은지(이하 soloStudyType), 팀플 또는 협업하여 코딩하기에 좋은지(이하 groupStudyType)에 대해 기록할 수 있는 것이죠. 만약 특정 카페를 soloStudyType으로 남긴 리뷰 수와 groupStudyType으로 남긴 리뷰 수가 같을 경우, 해당 카페는 두 가지 특징을 모두 가진 타입(이하 bothStudyType)이 됩니다. 작성자 입장에선 soloStudyType, groupStudyType 뿐이지만 서버 측에서 처리할 때에는 bothStudyType까지 같이 있는 셈이죠. 그렇다 보니 enum 클래스 처리나 Database 단에서의 처리가 복잡하게 돼, 위와 같이 단순 분기문으로 처리하게 됐습니다.
문제는 studyTypeRepository.findAllByCafeIdAndStudyTypeValue() 메서드에서 발생합니다.
해당 카페의 id 값과 soloStudyType 또는 groupStudyType 값을 가진 StudyType들을 모두 조회하는 쿼리입니다.
모카콩의 백엔드 서버에서는 Spring Data JPA를 사용합니다. 그렇기 때문에 해당 작업은 left outer join 이 발생하게 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# studyTypeRepository.findAllByCafeIdAndStudyTypeValue(cafeId, SOLO_STUDY_TYPE);
Hibernate:
select
studytype0_.study_type_id as study_ty1_5_,
studytype0_.cafe_id as cafe_id3_5_,
studytype0_.member_id as member_i4_5_,
studytype0_.study_type_value as study_ty2_5_
from
study_type studytype0_
left outer join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
# studyTypeRepository.findAllByCafeIdAndStudyTypeValue(cafeId, GROUP_STUDY_TYPE);
Hibernate:
select
studytype0_.study_type_id as study_ty1_5_,
studytype0_.cafe_id as cafe_id3_5_,
studytype0_.member_id as member_i4_5_,
studytype0_.study_type_value as study_ty2_5_
from
study_type studytype0_
left outer join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
|
cs |
StudyType과 Cafe 간에 left outer join이 발생합니다.
Cafe 내에 작성된 리뷰로 인한 StudyType를 조회하는 것이기 때문에 inner join으로도 충분한데 말이죠.
Spring Data JPA의 불필요한 left outer join절 발생에 대해서는 제 블로그 내용을 캡처하여 대체하겠습니다.

(제 블로그 포스팅이므로 클릭해주시면 감사합니다 ㅎㅎㅎ 😅)
또, 지나치게 많은 정보를 조회하고 있다는 단점도 존재합니다. 해당 메서드를 사용하는 이유는 단순히 soloStudyType이 많은지, groupStudyType이 많은지 비교하기 위해서입니다. 즉, StudyType 테이블의 모든 컬럼을 조회할 필요가 없다는 것이죠. 하지만 위 쿼리에서는 select all로 모든 컬럼을 조회하고 있습니다. select로 조회하는 컬럼 개수를 유의미하게 줄여 쿼리 튜닝을 할 수 있어보입니다. 잘만 튜닝한다면 커버링 인덱스가 사용되게 하여 실행계획의 extra에 USING INDEX가 뜰 수 있을 수도 있겠죠.
2. 리뷰 작성 시에 이미 해당 카페에 리뷰를 작성했는지 확인하는 과정
사실 문제는 위 로직뿐만이 아닙니다. 어떻게 보면 이제 소개드릴 로직이 더 느리다고 볼 수도 있습니다.
지금 소개해드릴 로직의 목적 자체는 간단합니다. 해당 카페에 특정 사람이 이미 리뷰를 작성했는지 확인하는 과정을 거칩니다. 모카콩에서는 특정 카페에 한 사람이 두 개 이상의 리뷰를 작성할 수 없기 때문입니다. 바로 해당 메서드가 수행될 때 나가는 쿼리들을 살펴보죠.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
Hibernate:
select
review0_.review_id as review_i1_3_,
review0_.cafe_id as cafe_id8_3_,
review0_.desk as desk2_3_,
review0_.parking as parking3_3_,
review0_.power as power4_3_,
review0_.sound as sound5_3_,
review0_.toilet as toilet6_3_,
review0_.wifi as wifi7_3_,
review0_.member_id as member_i9_3_,
review0_.study_type_id as study_t10_3_
from
review review0_
left outer join
cafe cafe1_
on review0_.cafe_id=cafe1_.cafe_id
left outer join
member member2_
on review0_.member_id=member2_.member_id
where
cafe1_.cafe_id=?
and member2_.member_id=?
|
cs |
Review 테이블과 Cafe 테이블끼리 left outer join이, Review 테이블과 Member 테이블끼리 left outer join이 발생합니다.
해당 카페에 남겨진 리뷰들을 조회하는 것이므로 Cafe-Review 간에 inner join으로도 충분하고, 특정 멤버가 남긴 리뷰들을 조회하는 것이므로 Member-Review 간 inner join으로도 충분한데 말이죠.
뿐만 아니라, 여기서도 불필요한 컬럼들을 지나치게 많이 조회하고 있습니다. 단순히 리뷰가 작성했는지 여부만 파악해도 되는데 리뷰의 정보들을 모두 가져오고 있습니다.
해결 방법 1. Fetch Join을 이용한다.
위에서 언급했던 문제 중, 리뷰 작성 후 카페의 StudyType을 갱신하는 로직에 대해서만 살펴보겠습니다. 이미 리뷰를 작성했는지 확인하는 로직도 이와 비슷하게 해결하였기 때문에, 하나의 예시를 보는 것만으로도 충분하리라 생각합니다.
Spring Data JPA 특성 상 발생하는 left outer join이 문제가 되는 상황이므로 @Query 어노테이션으로 직접 JPQL을 통해 조회하여 해당 문제를 해결할 수 있습니다.
|
1
2
3
4
|
@Query("select s from StudyType s " +
"join fetch s.cafe c " +
"where c.id = :cafeId and s.studyTypeValue = :studyTypeValue")
List<StudyType> findAllByCafeIdAndStudyTypeValue(Long cafeId, String studyTypeValue);
|
cs |
left outer join 이 없어졌는지 한 번 확인해볼까요?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
Hibernate:
select
studytype0_.study_type_id as study_ty1_5_0_,
cafe1_.cafe_id as cafe_id1_0_1_,
studytype0_.cafe_id as cafe_id3_5_0_,
studytype0_.member_id as member_i4_5_0_,
studytype0_.study_type_value as study_ty2_5_0_,
cafe1_.desk as desk2_0_1_,
cafe1_.parking as parking3_0_1_,
cafe1_.power as power4_0_1_,
cafe1_.sound as sound5_0_1_,
cafe1_.toilet as toilet6_0_1_,
cafe1_.wifi as wifi7_0_1_,
cafe1_.map_id as map_id8_0_1_,
cafe1_.name as name9_0_1_
from
study_type studytype0_
inner join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
Hibernate:
select
studytype0_.study_type_id as study_ty1_5_0_,
cafe1_.cafe_id as cafe_id1_0_1_,
studytype0_.cafe_id as cafe_id3_5_0_,
studytype0_.member_id as member_i4_5_0_,
studytype0_.study_type_value as study_ty2_5_0_,
cafe1_.desk as desk2_0_1_,
cafe1_.parking as parking3_0_1_,
cafe1_.power as power4_0_1_,
cafe1_.sound as sound5_0_1_,
cafe1_.toilet as toilet6_0_1_,
cafe1_.wifi as wifi7_0_1_,
cafe1_.map_id as map_id8_0_1_,
cafe1_.name as name9_0_1_
from
study_type studytype0_
inner join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
|
cs |
left outer join 대신 inner join 쿼리가 나가도록 리팩터링에 성공했습니다!
fetch join은 Spring Data JPA의 N+1 문제를 예방할 수 있다는 장점도 가지고 있습니다. 현재 모카콩의 로직에서는 JPA의 지연로딩을 이용하여 N+1 문제가 발생하고 있진 않습니다. 하지만 결과로 찾아온 객체의 값을 꺼내는 로직이 추가되게 된다면 언제든지 N+1 문제는 발생할 수 있습니다. 그렇기 때문에 해당 문제의 예방책으로라도 fetch join은 좋은 선택지가 될 수 있습니다.
그런데 fetch join 특성 상 select로 조회하는 컬럼은 매우 많아지게 됐습니다. 아까 위에서 언급했던 문제점 중 아래 문제를 기억하시나요?
또, 지나치게 많은 정보를 조회하고 있다는 단점도 존재합니다. 해당 메서드를 사용하는 이유는 단순히 soloStudyType이 많은지,
groupStudyType이 많은지 비교하기 위해서입니다.
즉, StudyType 테이블의 모든 컬럼을 조회할 필요가 없다는 것이죠. 하지만 위 쿼리에서는 select all로 모든 컬럼을 조회하고 있습니다. select로 조회하는 컬럼 개수를 유의미하게 줄여 쿼리 튜닝을 할 수 있어보입니다.
그렇습니다. fetch join을 이용함으로써 left outer join을 해결하고 N+1 문제의 예방책을 미리 세워둔들, 가장 근본적인 문제가 해결되지 않았습니다. 바로 지나치게 많은 정보를 조회하고 있다는 단점이죠. 심지어 join이 발생한 Entity Set의 컬럼들을 모두 조회하는 fetch join 특성 상, 리팩터링 전보다 더 많은 불필요한 정보를 조회하고 있어 오히려 성능이 좋지 않아질 수도 있습니다.
어떻게 하면 좋을까요? 아래에서 해당 문제를 해결해보겠습니다.
해결 방법 2-1. 필요한 컬럼만을 조회하도록 한다.
지나치게 많은 컬럼들이 조회되고 있다면, 필요한 정보들만 조회하도록 쿼리를 바꾸면 됩니다.
단순하지만 효과적인 해결책 아닌가요? 실제로 많은 개발자들이 select * 구문을 지양하는 이유입니다.
|
1
2
3
4
5
|
@Query("select s.studyTypeValue " +
"from StudyType s " +
"join s.cafe c " +
"where c.id = :cafeId and s.studyTypeValue = :studyTypeValue")
List<String> findAllByCafeIdAndStudyTypeValue(Long cafeId, String studyTypeValue);
|
cs |
한번 조회되는 쿼리를 살펴보죠.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
Hibernate:
select
studytype0_.study_type_value as col_0_0_
from
study_type studytype0_
inner join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
Hibernate:
select
studytype0_.study_type_value as col_0_0_
from
study_type studytype0_
inner join
cafe cafe1_
on studytype0_.cafe_id=cafe1_.cafe_id
where
cafe1_.cafe_id=?
and studytype0_.study_type_value=?
|
cs |
확실히 조회되는 컬럼 개수가 줄었다는게 느껴지시지 않나요?
이전의 쿼리랑 한번 비교해보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 쿼리 개선 이전
Hibernate:
select
studytype0_.study_type_id as study_ty1_5_0_,
cafe1_.cafe_id as cafe_id1_0_1_,
studytype0_.cafe_id as cafe_id3_5_0_,
studytype0_.member_id as member_i4_5_0_,
studytype0_.study_type_value as study_ty2_5_0_,
cafe1_.desk as desk2_0_1_,
cafe1_.parking as parking3_0_1_,
cafe1_.power as power4_0_1_,
cafe1_.sound as sound5_0_1_,
cafe1_.toilet as toilet6_0_1_,
cafe1_.wifi as wifi7_0_1_,
cafe1_.map_id as map_id8_0_1_,
cafe1_.name as name9_0_1_
# 쿼리 개선 이후
Hibernate:
select
studytype0_.study_type_value as col_0_0_
|
cs |
13개의 컬럼을 모두 조회했던 이전 쿼리와 달리, 1개의 컬럼만 조회하는 쿼리가 생성됐습니다! 컬럼의 개수를 줄여서 DB 부하를 조금이나마 줄일 수 있었습니다.
해결 방법 2-2. 필요한 컬럼, 그 중에서도 인덱스를 타는 값만을 조회하도록 한다.
fetch join 방법은 studyType 갱신 로직, 리뷰를 이미 작성했는지 확인하는 로직의 리팩터링 결과가 비슷했기 때문에 후자의 예시는 들지 않았습니다. 하지만 여기서는 두 로직에서의 결과가 서로 다르기 때문에, 이번에는 후자의 예시도 들어보도록 하겠습니다.
리뷰를 이미 작성했는지 확인하는 로직, 기억나시나요?
해당 로직의 리팩터링 전 발생 쿼리가 기억나지 않으실 것 같아 한번 가져와보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# AS-IS
Hibernate:
select
review0_.review_id as review_i1_3_,
review0_.cafe_id as cafe_id8_3_,
review0_.desk as desk2_3_,
review0_.parking as parking3_3_,
review0_.power as power4_3_,
review0_.sound as sound5_3_,
review0_.toilet as toilet6_3_,
review0_.wifi as wifi7_3_,
review0_.member_id as member_i9_3_,
review0_.study_type_id as study_t10_3_
# TO-DO
Hibernate:
select
review0_.review_id as col_0_0_
|
cs |
우리는 리뷰를 이미 작성했는지 확인만 하면 됩니다. 그렇기 때문에 해당 쿼리의 결과로 리뷰의 모든 컬럼이 필요한 것이 아닙니다. 쿼리가 존재하는지 자체만 확인하면 됩니다.
그렇기 때문에 review.id만 조회하도록 아래와 같이 쿼리를 개선했습니다. 위에서와 마찬가지로 불필요한 쿼리 조회 결과의 컬럼 개수를 줄이기 위해서입니다.
|
1
2
3
4
5
6
|
@Query("select r.id " +
"from Review r " +
"join r.cafe c " +
"join r.member m " +
"where c.id = :cafeId and m.id = :memberId")
Optional<Long> findIdByCafeIdAndMemberId(Long cafeId, Long memberId);
|
cs |
해당 개선된 JPQL의 결과는 아래와 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
Hibernate:
select
review0_.review_id as col_0_0_
from
review review0_
inner join
cafe cafe1_
on review0_.cafe_id=cafe1_.cafe_id
inner join
member member2_
on review0_.member_id=member2_.member_id
where
cafe1_.cafe_id=?
and member2_.member_id=?
|
cs |
컬럼 개수가 확연히 줄어든 것을 확인할 수 있습니다.
자, 근데 이 결과가 아까 예시로 든 studyType 갱신 로직의 리팩터링 결과와 무엇이 다르냐!
정답은 바로 커버링 인덱스를 사용한다는 점입니다. 커버링 인덱스에 대해 궁금하다면 아래 글을 참고해주세요.
https://tecoble.techcourse.co.kr/post/2021-10-12-covering-index/
커버링 인덱스
조회 성능 개선 미션을 진행하며 를 알게 됐다. 처음 보는 단어여서 이게 어떤 인덱스일까 궁금했고, 바로 찾아보고 이해했다. 그러면서 한번 내용을 글로 정리하면 좋을 것 같다는 생각을 했다.
tecoble.techcourse.co.kr
MySQL은 primary_key에 default로 index를 걸어줍니다. 그렇기 때문에 select 대상으로 primary_key만 존재한다는 것은 select 대상으로 인덱스가 걸린 대상만 존재한다는 것과 같습니다. 즉, 커버링 인덱스를 사용하게 됩니다!
한번 explain 키워드로 실행 계획을 살펴볼까요?
리팩터링한 쿼리의 실행계획
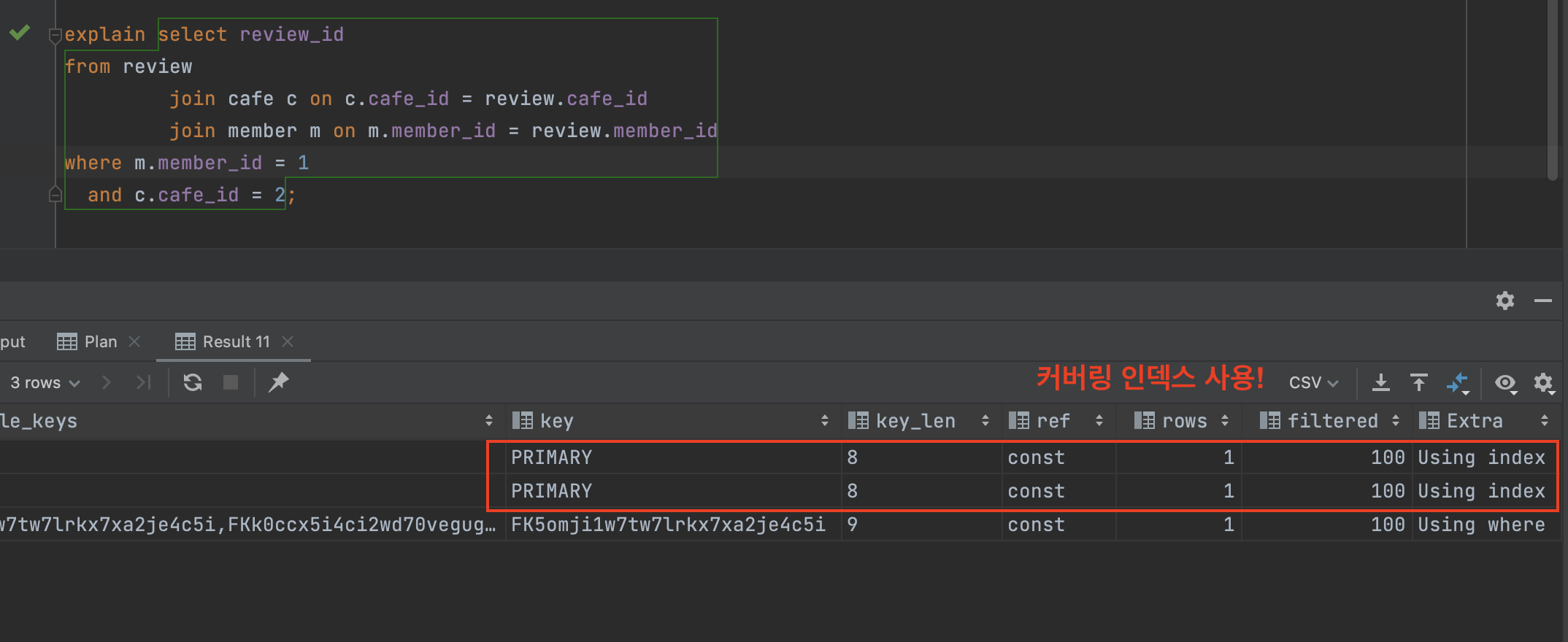
데이터 수가 많지 않아서 cost를 비교하기보단, Extra를 확인하는 것에 집중했습니다. Extra를 잘 보시면 Using index라는 결과가 출력되었습니다. 이는 커버링 인덱스를 타서 더 빠른 속도로 쿼리 결과를 반환했다는 뜻에 해당됩니다!
한번 리팩터링하기 전의 쿼리 실행 계획을 살펴볼까요?
리팩터링 전 쿼리 실행 계획
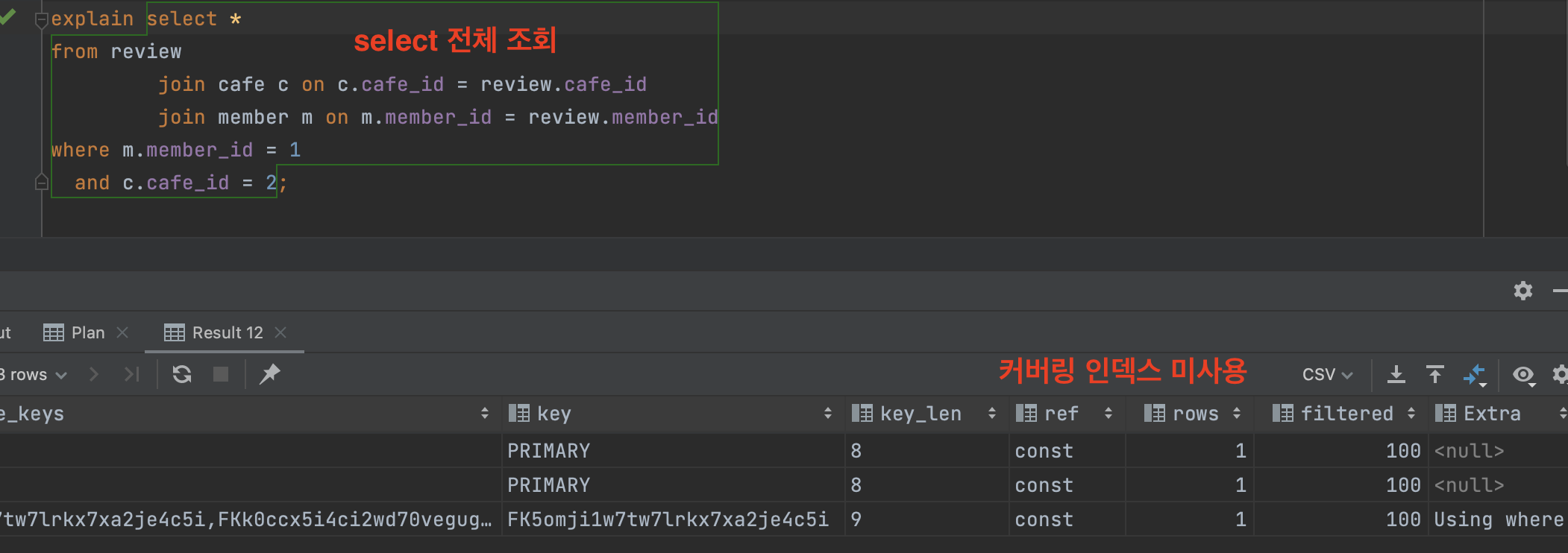
Extra의 결과로 null이 발생했습니다. (참고로 Using Where은 where절 필터링이 들어가면 발생하는 결과로, 리팩터링 전후가 동일합니다.) 즉, 커버링 인덱스를 타지 않고 직접 데이터 파일을 읽어야되는 상황입니다. 리팩터링하기 전과 후가 엄청난 성능차이를 보이는 것입니다!
마치며
지금은 모카콩의 데이터 수가 많지 않아, 쿼리의 성능에 따른 서버 속도 차이가 실감이 되지 않습니다. (심지어 아직 배포하기도 전인 상황이여서 실 사용자가 없으므로 더더욱 그럴 듯합니다.)
데이터가 좀 쌓이면 위 쿼리와 exists 쿼리와의 성능 비교도 진행해보고 싶습니다. 글을 읽으시면서 review.id를 조회하는 것이 아닌 exists 쿼리로 리뷰가 존재하는지 확인하면 되지 않을까? 생각하신 분들이 있을 수 있습니다. 맞습니다. 사실 exists 쿼리의 엄청난 속도를 생각한다면, 그리고 요구사항을 생각해본다면 exist 쿼리가 더 적합해보일 수도 있다는 생각이 듭니다. 이후에 데이터가 쌓인다면 exists 쿼리랑 비교하여 위키에 작성해보도록 하겠습니다. (참고로 count(*) 쿼리와 비교하지 않는 이유는, count(*) 쿼리보다 exists 쿼리가 훨씬 빠르기 때문입니다.)
지금의 포스팅이 앞으로 배포하고 나서 데이터가 많이 쌓였을 때 의미있길 바라며, 이번 위키 작성을 마치도록 하겠습니다.
'JAVA > JPA 학습기록' 카테고리의 다른 글
| [Spring Data JPA] Custom Repository 구현체 클래스명 주의점 (0) | 2024.07.19 |
|---|---|
| [JPA] unique 동시성 이슈 해결 및 CountDownLatch 테스트 작성 (Feat. Unique Index) (18) | 2023.06.04 |
| [ERROR] JPA initializationError 해결 방법 모음 및 대처법 (0) | 2023.02.10 |
| [JPA] 프로젝트 동시성 이슈 해결을 위해 낙관적 락을 걸어보았다 (3) | 2022.10.29 |
| [QueryDSL] queryDSL 프로젝트 적용 후기 및 트러블슈팅 (2) | 2022.09.17 |